앞서 포스팅한 스마트러닝 시스템을 개발하기 위해서 저희는 주요 서비스인 전사 자료의 핵심인 통역 음성을 그대로 받아쓰는 기능을 구현했습니다.
이화여대 통번역대학원 스마트러닝 시스템
안녕하세요, 이화여대 컴퓨터공학과 그로쓰3팀 주제 설명 드리겠습니다. 현재 이화여대 통번역대학원에서는 통역 과제 수행시 업로드된 원본음성을 학습자가 들으며 통역을 하고 녹음한 통역
youdaeng-com.tistory.com
통역 음성을 그대로 받아쓰기 위해서는 통역 음성에서 나타나는 추임새, 침묵을 전사 자료에 표시하고 문맥에 따라 STT 결과가 교정되지 않도록 해야 했습니다.
저희는 음성이 추임새인지 확인하기 위해 1) 추임새/비추임새 구분 모델(Filler determine model)과 2) 추임새 종류를 판별(Filler classifier model) 해주는 총 2가지의 CNN 인공지능 모델을 구현했습니다. 추임새를 판단하기 위해 두 가지 모델을 분리한 이유는 한 가지 모델만을 사용하면 output이 총 4개(어, 음, 그 비추임새)라 비추임새로 태깅하는 정확도가 더 필요한 상황에서 output이 4개인 것은 부적절하다고 판단했습니다. 따라서 추임새/비추임새 구분 모델(Output: 추임새, 비추임새)로 일단 추임새 여부를 확인하고 그 다음 추임새의 종류(Output:어, 음, 그)를 판별하는 방식으로 진행했습니다.
시작하기 앞서 저희 팀 깃허브를 공유합니다!
그로스3팀
그로스3팀 has 3 repositories available. Follow their code on GitHub.
github.com
1. 학습 데이터 수집
먼저 학습 데이터를 수집했습니다.
음성 데이터는 다양한 연령대, 성별, 다양한 음성 길이, 높낮이를 고려해서 추임새(어, 음, 그) 2500여개, 비추임새(외) 2000여개를 수집했습니다. 아래는 저희가 수집한 음성 파일입니다.

학습 데이터가 충분하지 않은 상황에서 예측 결과 종류가 2개, 3개 뿐이기 때문에 9:1로 학습시키기로 결정했습니다.
2. 음성 데이터 특징 추출
음성 데이터를 학습하기 위해서는 아래와 같이 아날로그 데이터인 음성 데이터를 디지털 신호로 변환해야 합니다.

음성 데이터를 특징 벡터화 해주는 알고리즘에는 MFCC가 있습니다. 파이썬에서 제공하는 librosa 라이브러리를 이용해 간단히 특징을 추출할 수 있습니다.
1) 음성데이터 load 하기
MFCC로 특징을 추출하기 위해서는 librosa 라이브러리를 사용해 음성 데이터를 load 해야 합니다.
audio, sr = librosa.load(audio_file, sr=16000)
print('sr:', sr, ', audio shape:', audio.shape)
print('length:', audio.shape[0]/float(sr), 'secs')
sr은 sampling rate로 초당 16000개의 샘플을 가지고 있는 데이터라는 의미입니다. 따라서 audio shape와 sr을 이용해서 오디오 길이 계산을 할 수 있습니다. 다음과 같이요!

2) MFCC로 특징 추출하기
음성 데이터를 load 했으면 이 음성 데이터의 특징을 추출해야 합니다. 마찬가지로 librosa 라이브러리로 간단히 특징을 추출할 수 있습니다.
mfcc = librosa.feature.mfcc(wav)
위의 코드로 간단히 특징을 추출할 수 있고 여러 parameter를 사용해 default값을 조정할 수 있습니다.
parameter들의 자세한 설명은 여기에서 확인할 수 있습니다.
저희 팀이 사용한 parameter를 간단히 설명하면 다음과 같습니다.
① sr
sampling rate를 말합니다. default값은 22050Hz입니다. 저희는 앞서 음성 데이터를 load 할 때 sr을 16000Hz으로 했기 때문에 꼭 sr=16000을 파라미터로 삽입해야 합니다. (사람의 목소리는 대부분 16000Hz 안에 포함된다고 합니다)
② n_mfcc
return 될 mfcc의 개수를 정해주는 파라미터입니다. default값은 20입니다. 더 다양한 데이터 특징을 추출하기 위해서 이를 100까지 증가 시켰습니다.
③ n_fft
frame의 length를 결정하는 파라미터 입니다. n_fft를 설정하면 window size가 자동으로 같은 값으로 설정되는데 window size의 크기로 잘린 음성이 n_fft보다 작은 경우 0으로 padding을 붙여주는 작업을 하기 때문에 n_fft는 window size보다 크거나 같아야 합니다.
일반적으로 자연어 처리에서는 음성을 25m의 크기를 기본으로 하고 있으며 16000Hz인 음성에서는 400에 해당하는 값입니다. (16000 * 0.025 = 400) 즉, n_fft는 sr에 frame_length인 0.025를 곱한 값입니다.
④ hop_length
hop_length의 길이만큼 옆으로 가면서 데이터를 읽습니다. 10ms를 기본으로 하고 있어 16000Hz인 음성에서는 160에 해당합니다. (16000 * 0.01 = 160) 즉, hop_length는 sr에 frame_stride인 0.01를 곱해서 구할 수 있습니다.
window_length가 0.025이고 frame_stride가 0.01이라고 하면 0.015초씩은 데이터를 겹치면서 읽는다고 생각하면 됩니다.
위의 파라미터를 변경한 것을 모두 합치면 아래와 같습니다.
mfcc = librosa.feature.mfcc(audio, sr=16000, n_mfcc=100, n_fft=400, hop_length=160)
추출한 mfcc를 다음과 같이 sklearn 라이브러리를 이용해 전처리 scaling을 합니다.
mfcc = sklearn.preprocessing.scale(mfcc, axis=1)
그다음은 model에 들어갈 input shape를 조정하기 위해서 일정 범위까지만 데이터를 보는 작업을 추가합니다. 즉, input의 길이보다 긴 경우는 자르고 짧은 경우는 padding을 붙여서 크기를 조절하는 것입니다. 이 과정이 필요한 이유는 저희가 모은 음성 데이터의 길이가 일정하지 않고 다양한 길이를 가졌기 때문입니다. 모은 음성데이터의 길이 평균이 0.4-0.5초이므로 이 길이를 40으로 정했습니다. 40은 실제로 0.46초 정도를 의미합니다.
pad2d = lambda a, i: a[:, 0:i] if a.shape[1] > i else np.hstack((a, np.zeros((a.shape[0], i-a.shape[1]))))
padded_mfcc = pad2d(mfcc, 40)
shape가 수정됨을 알 수 있습니다.

3) 시각화하기
모든 mfcc 특징 추출 전처리가 끝났습니다. 그럼 이걸 시각화해서 볼까요? 역시 librosa 라이브러리로 간단히 살펴볼 수 있습니다.
librosa.display.specshow(padded_mfcc, sr=16000, x_axis='time')
어, 음, 그 추임새 데이터를 각각 시각화하면 다음과 같습니다. 비슷하면서도 다른 양상을 가진다는 것을 알 수 있습니다.

3. CNN model 학습시키기 & 예측 결과 확인
먼저 1) 추임새/비추임새 구분 모델(Filler determine model)과 2) 추임새 종류를 판별(Filler classifier model) 중 추임새 종류를 판별(Filler classifier model)해주는 모델부터 설명하겠습니다. 앞서 한 음성 파일의 mfcc 특징 추출을 하는 법을 알았다면, 이걸 모든 train/test 데이터에 적용해야 합니다. 아래 코드들로 모든 train/test 데이터에 대해 mfcc 특징을 추출한 np array를 구할 수 있습니다.
# train data를 넣는다.
for filename in os.listdir(DATA_DIR + "train2/"):
filename = normalize('NFC', filename)
try:
# wav 포맷 데이터만 사용
if '.wav' not in filename in filename:
continue
audio, sr = librosa.load(DATA_DIR+ "train2/"+ filename, sr=16000)
mfcc = librosa.feature.mfcc(audio, sr=16000, n_mfcc=100, n_fft=400, hop_length=160)
mfcc = sklearn.preprocessing.scale(mfcc, axis=1)
padded_mfcc = pad2d(mfcc, 40)
# 추임새 별로 dataset에 추가
if filename[0] == '어':
trainset.append((padded_mfcc, 0))
elif filename[0] == '음':
trainset.append((padded_mfcc, 1))
elif filename[0] == '그':
trainset.append((padded_mfcc, 2))
except Exception as e:
print(filename, e)
raise
# 학습 데이터를 무작위로 섞는다.
random.shuffle(trainset)
# test data를 넣는다.
for filename in os.listdir(DATA_DIR + "test2/"):
filename = normalize('NFC', filename)
try:
# wav 포맷 데이터만 사용
if '.wav' not in filename in filename:
continue
audio, sr = librosa.load(DATA_DIR+ "test2/"+ filename, sr=16000)
mfcc = librosa.feature.mfcc(audio, sr=16000, n_mfcc=100, n_fft=400, hop_length=160)
mfcc = sklearn.preprocessing.scale(mfcc, axis=1)
padded_mfcc = pad2d(mfcc, 40)
# 추임새 별로 test dataset에 추가
if filename[0] == '어':
testset.append((padded_mfcc, 0))
elif filename[0] == '음':
testset.append((padded_mfcc, 1))
elif filename[0] == '그':
testset.append((padded_mfcc, 2))
except Exception as e:
print(filename, e)
raise
# 테스트 데이터를 무작위로 섞는다.
random.shuffle(testset)
train_mfccs = [a for (a,b) in trainset]
train_y = [b for (a,b) in trainset]
test_mfccs = [a for (a,b) in testset]
test_y = [b for (a,b) in testset]
train_mfccs = np.array(train_mfccs)
train_y = to_categorical(np.array(train_y))
test_mfccs = np.array(test_mfccs)
test_y = to_categorical(np.array(test_y))
print('train_mfccs:', train_mfccs.shape)
print('train_y:', train_y.shape)
print('test_mfccs:', test_mfccs.shape)
print('test_y:', test_y.shape)
train_X_ex = np.expand_dims(train_mfccs, -1)
test_X_ex = np.expand_dims(test_mfccs, -1)
print('train X shape:', train_X_ex.shape)
print('test X shape:', test_X_ex.shape)
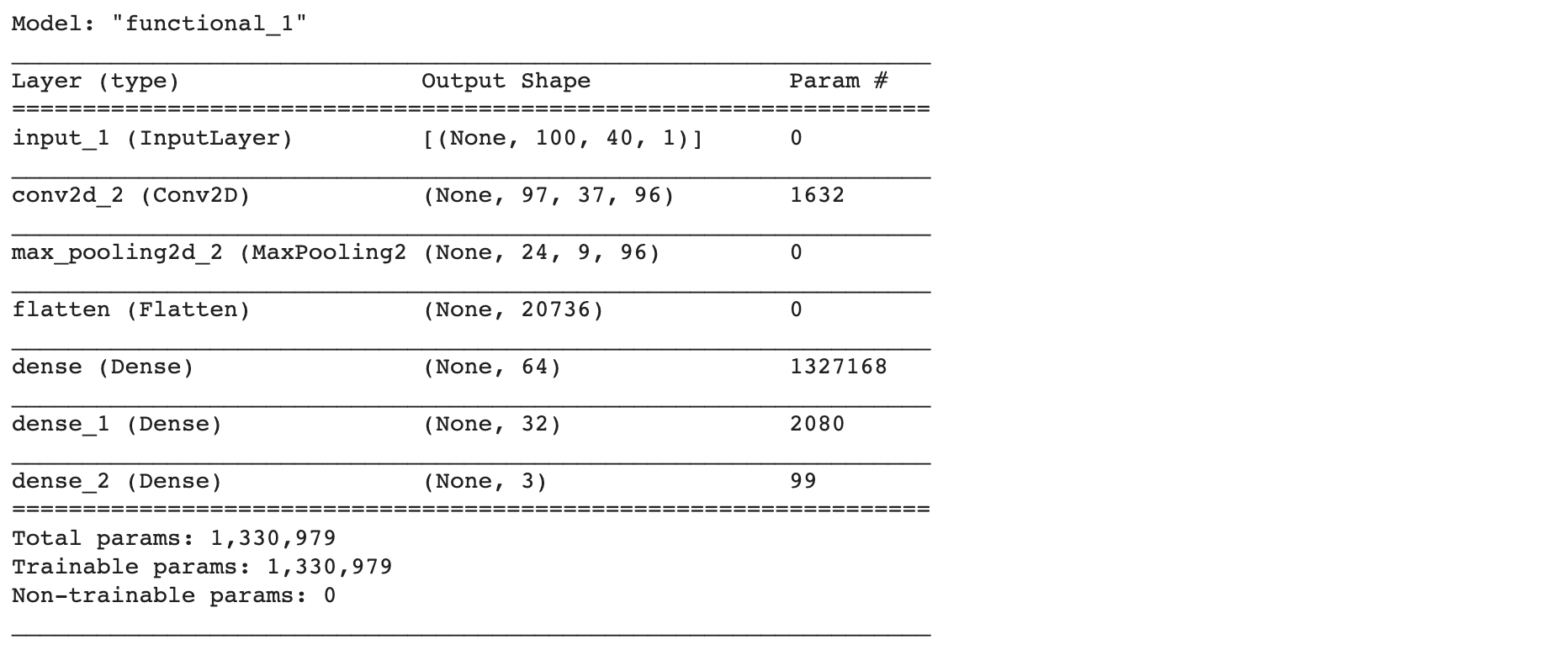
학습 데이터와 테스트 데이터가 모두 준비되면 모델의 층을 쌓고 학습합니다.
저희는 Conv2D, MaxPooling2D를 각각 3개씩 쌓고 Flatten층, Dense 3개의 층을 쌓았습니다.
ip = Input(shape=train_X_ex[0].shape)
m = Conv2D(32, kernel_size=(4,4), activation='relu')(ip)
m = MaxPooling2D(pool_size=(4,4))(m)
m = Conv2D(32*2, kernel_size=(4,4), activation='relu')(ip)
m = MaxPooling2D(pool_size=(4,4))(m)
m = Conv2D(32*3, kernel_size=(4,4), activation='relu')(ip)
m = MaxPooling2D(pool_size=(4,4))(m)
m = Flatten()(m)
m = Dense(64, activation='relu')(m)
m = Dense(32, activation='relu')(m)
op = Dense(3, activation='softmax')(m)
model = Model(ip, op)
model.summary()
이제 학습한 모델로 실제 샘플 데이터를 넣어서 정확히 판별되는지 확인해보겠습니다. 똑같은 방식으로 mfcc 특징을 추출하고 전처리 scaling을 하고 pad2d 함수를 사용합니다. 그다음은 모델에 input으로 넣기 위해서 numpy 라이브러리의 expand_dims()를 사용해 차원을 추가합니다. 이제 이 데이터를 predict 함수에 넣습니다.
audio, sr = librosa.load('/content/그603.wav')
mfcc = librosa.feature.mfcc(audio, sr=16000, n_mfcc=100, n_fft=400, hop_length=160)
mfcc = sklearn.preprocessing.scale(mfcc, axis=1)
padded_mfcc = pad2d(mfcc, 40)
padded_mfcc= np.expand_dims(padded_mfcc, 0)
model.predict(padded_mfcc)
그럼 결과는 다음과 같아요, 3개의 Output 중에서 가장 큰 값이 최종 결과라고 생각하시면 됩니다. (어, 음, 그 순서대로!)

'그'가 가장 큰 값을 가진다는 것을 알 수 있네요!
이 과정을 함수화하면 다음과 같습니다.
def predict_filler_type(audio_file):
# 추임새 종류 판별을 위한 임시 음성 파일 생성
audio_file.export("temp.wav", format="wav")
audio, sr = librosa.load("temp.wav", sr=16000)
mfcc = librosa.feature.mfcc(audio, sr=16000, n_mfcc=100, n_fft=400, hop_length=160)
mfcc = sklearn.preprocessing.scale(mfcc, axis=1)
padded_mfcc = pad2d(mfcc, 40)
padded_mfcc = np.expand_dims(padded_mfcc, 0)
result = filler_classifier_model.predict(padded_mfcc)
# 판별 완료된 음성 파일 삭제
os.remove("temp.wav")
return np.argmax(result)
추임새/비추임새 구분 모델(Filler determine model)도 앞선 모델과 과정이 같습니다. 다만 Output이 추임새, 비추임새 두 가지로 나눠진다는 차이가 있습니다. 따라서 앞서 train/test 데이터를 추임새(어, 음, 그)/비추임새(외)로 모아야겠죠?! 같은 방식으로 mfcc 추출하고~~ 모으면 됩니다. 전체 코드는 저희 팀 깃허브에서 확인해주세요!
그럼 모델을 사용해서 하나의 음성 데이터가 추임새인지 여부를 판별하는 코드는 다음과 같습니다.
def predict_filler(audio_file):
# 추임새 판별을 위한 임시 음성 파일 생성
audio_file.export("temp.wav", format="wav")
audio, sr = librosa.load("temp.wav", sr=16000)
mfcc = librosa.feature.mfcc(audio, sr=16000, n_mfcc=100, n_fft=400, hop_length=160)
mfcc = sklearn.preprocessing.scale(mfcc, axis=1)
padded_mfcc = pad2d(mfcc, 40)
padded_mfcc = np.expand_dims(padded_mfcc, 0)
result = filler_determine_model.predict(padded_mfcc)
# 판별 완료된 음성 파일 삭제
os.remove("temp.wav")
if result[0][0] >= result[0][1]: # 추임새
return 0
else:
return 1
모델에 대한 전체 코드는 저희 팀 깃허브에서 확인하실 수 있습니다. 블로그에 생략된 코드가 많기 때문에 꼭 확인해주세요!
4. 전사 알고리즘 API
전사 알고리즘의 핵심은 음성을 여러 구간으로 나누어 침묵, 추임새, 비추임새로 각각 태깅하고 다른 방법으로 텍스트 변환을 하는 것입니다. 아래 그림을 참고해주세요!


1) 침묵, 비침묵 구간 분리
첫 번째는 파형 분석으로 침묵과 비침묵으로 구간을 나누는 것입니다. pydub.silence의 라이브러리로 쉽게 silence와 nonsilence 부분을 구분할 수 있습니다.
min_silence_length = 70
intervals = detect_nonsilent(audio_file, min_silence_len=min_silence_length, silence_thresh=-32.64)
intervals 변수에는 비침묵 구간의 처음과 끝이 리스트 형태로 return 됩니다. 침묵 구간에 대해서는 0000을 태깅합니다.
저희는 전사 알고리즘을 처리할 때 3가지의 문제점을 발견합니다.
그중 첫 번째는 학습 데이터와 실제 모델에 들어가는 데이터의 차이 때문에 예측 결과가 정확하지 않다는 것입니다. 학습 데이터는 사람이 음절 단위로 녹음한 음성인 반면, 실제 모델에 들어가는 데이터는 연속되는 말을 침묵을 기준으로 자른 것이기 때문에 각 음절이 정확하게 분리되지 않았습니다. 그래서 min_silence_len, silence_thresh 값 등을 조정해 음성이 최대한 단어 또는 음절 단위로 잘라지도록 했습니다.
또 detech_nonsilent가 침묵을 기준으로 음성을 분할할 때 비침묵 구간의 음성의 앞/뒤가 지나치게 잘려 실제 이를 stt로 텍스트화 했을 때 인식 불가가 되는 경우가 있었습니다. 이를 해결하기 위해 앞/뒤에 padding을 0.2초를 두어 보완했습니다. 마지막으로 0.8초 이상의 침묵에 대해서만 해당 태깅을 합니다.
나중에 비침묵 구간에 대해서 stt를 사용해 텍스트 변환을 할 때 너무 짧은 단위로 음성이 분리되어 stt가 인식이 불가능한 것을 방지하기 위함입니다.
2) 비침묵 구간에 추임새 모델 적용하기
비침묵 구간에 앞서 살펴본 인공지능 모델들을 사용합니다. 먼저 추임새/비추임새 구분 모델(Filler determine model)로 추임새 여부를 판단하고 추임새가 아니면 비침묵 구간(1000)으로 태깅해줍니다. 만약 추임새이면 추임새 구간(1111)으로 태깅을 해주고 추임새 종류를 판별(Filler classifier model)를 사용해 해당 추임새의 종류(어:1001, 음:1010, 그:1100)를 태깅해줍니다.
두 번째 문제는 여기서 발생합니다. 한 음절로 분리된 구간 안에서 추임새와 비추임새가 연이어 나타나는 경우(ex. 그--밥을) 뒤의 비추임새(밥을)까지 추임새로 판명이 나서 전체가 추임새 태깅이 붙기 때문에 비추임새(밥을)가 태깅이 되지 않아 비추임새에 대한 stt가 적용되지 않는다는 것입니다. 이럴 경우 '그--밥을 먹는다'가 '그 먹는다'로 전사화 됩니다. 이를 해결하기 위해 재귀적으로 threshold를 조절하여 한 구간 내의 추임새와 비추임새 음절이 추가적으로 분리될 수 있도록 했습니다.
def shorter_filler(json_result, audio_file, min_silence_len, start_time, non_silence_start):
# 침묵 길이를 더 짧게
min_silence_length = (int)(min_silence_len/1.2)
intervals = detect_nonsilent(audio_file,
min_silence_len=min_silence_length,
silence_thresh=-32.64
)
for interval in intervals:
interval_audio = audio_file[interval[0]:interval[1]]
# padding 40 길이 이상인 경우 더 짧게
if (interval[1]-interval[0] >= 460):
non_silence_start = shorter_filler(json_result, interval_audio, min_silence_length, interval[0]+start_time, non_silence_start)
else: # padding 40 길이보다 짧은 경우 predict
if predict_filler(interval_audio) == 0 : # 추임새인 경우
json_result.append({'start':non_silence_start,'end':start_time+interval[0],'tag':'1000'})
non_silence_start = start_time + interval[0]
# 추임새 tagging
json_result.append({'start':start_time+interval[0],'end':start_time+interval[1],'tag':'1111'})
return non_silence_start
이렇게 위의 두 가지 과정을 통해 각 구간 별 시작과 끝 시간, 태그로 구성된 json 형태의 array가 반환됩니다.

json을 만드는 코드는 다음과 같습니다.
def create_json(audio_file):
intervals_jsons = []
min_silence_length = 70
intervals = detect_nonsilent(audio_file,
min_silence_len=min_silence_length,
silence_thresh=-32.64
)
if intervals[0][0] != 0:
intervals_jsons.append({'start':0,'end':intervals[0][0],'tag':'0000'})
non_silence_start = intervals[0][0]
before_silence_start = intervals[0][1]
for interval in intervals:
interval_audio = audio_file[interval[0]:interval[1]]
# 800ms초 이상의 공백 부분 처리
if (interval[0]-before_silence_start) >= 800:
intervals_jsons.append({'start':non_silence_start,'end':before_silence_start+200,'tag':'1000'})
non_silence_start = interval[0]-200
intervals_jsons.append({'start':before_silence_start,'end':interval[0],'tag':'0000'})
if predict_filler(interval_audio) == 0 : # 추임새인 경우
if len(interval_audio) <= 460:
intervals_jsons.append({'start':non_silence_start,'end':interval[0],'tag':'1000'})
non_silence_start = interval[0]
intervals_jsons.append({'start':interval[0],'end':interval[1],'tag':'1111'})
else:
non_silence_start = shorter_filler(intervals_jsons, interval_audio, min_silence_length, interval[0], non_silence_start)
before_silence_start = interval[1]
if non_silence_start != len(audio_file):
intervals_jsons.append({'start':non_silence_start,'end':len(audio_file),'tag':'1000'})
return intervals_jsons
3) 태깅 결과에 따라 텍스트 변환
다음은 앞서 태깅한 결과에 따라 추임새는 추임새로, 침묵은 [..3초..] 등 침묵의 길이를, 비침묵 구간에 대해서는 stt를 적용해 텍스트화했습니다.
세 번째 문제는 여기서 발생합니다. 짧은 단어가 들어가 stt에서 인식불가 처리가 되는 경우가 많이 발생한다는 점입니다. 이를 해결하기 위해서 stt에서 인식불가가 나온 경우 뒤에 비침묵 구간과 함께 처리되도록 알고리즘을 구성했습니다.
또 통역 개시 지연시간을 구하기 위해서는 사람이 말하는 첫 단어 전까지의 침묵 시간을 측정해야 되는데 detect_nonsilent는 지지직 소리나 작은 소리에도 비침묵으로 구분했기 때문에 통역 개시 지연시간을 구하기 어려웠습니다. 따라서 추임새나 stt결과가 나오기 전까지는 모두 비침묵 구간으로 보아 통역 개시 지연시간을 하나로 통일했습니다.
예를 들어, '[..3초..] [..5초..] [..2초..] 밥을 먹었다'로 통역 개시 지연시간이 구분되던 것을 '[..10초..] 밥을 먹었다'로 통일했습니다.
그리고 통계를 보여주기 위해서 [어, 음, 그]의 추임새 개수, 통역 개시 지연시간, 침묵 시간, 발화시간을 전체 음성 대비 비율을 구했습니다.
def STT_with_json(audio_file, jsons):
first_silence = 0
num = 0
unrecognizable_start = 0
r = sr.Recognizer()
transcript_json = []
statistics_filler_json = []
statistics_silence_json = []
filler_1 = 0
filler_2 = 0
filler_3 = 0
audio_total_length = audio_file.duration_seconds
silence_interval = 0
for json in jsons :
if json['tag'] == '0000':
# 통역 개시 지연시간
if num == 0:
first_silence = first_silence + (json['end']-json['start'])/1000
else:
silence_interval = silence_interval + (json['end']-json['start'])/1000
silence = "(" + str(round((json['end']-json['start'])/1000)) + "초).."
transcript_json.append({'start':json['start'],'end':json['end'],'tag':'0000','result':silence})
elif json['tag'] == '1111':
# 통역 개시 지연시간
if num == 0:
silence = "(" + str(round(first_silence)) + "초).."
transcript_json.append({'start':0,'end':json['start'],'tag':'0000','result':silence})
first_silence_interval = first_silence
# 추임새(어, 음, 그) 구분
filler_type = predict_filler_type(audio_file[json['start']:json['end']])
if filler_type == 0 :
transcript_json.append({'start':json['start'],'end':json['end'],'tag':'1001','result':'어(추임새)'})
filler_1 = filler_1 + 1
elif filler_type == 1:
transcript_json.append({'start':json['start'],'end':json['end'],'tag':'1010','result':'음(추임새)'})
filler_2 = filler_2 + 1
else:
transcript_json.append({'start':json['start'],'end':json['end'],'tag':'1100','result':'그(추임새)'})
filler_3 = filler_3 + 1
num = num + 1
elif json['tag'] == '1000':
# 인식불가 처리
if unrecognizable_start != 0:
audio_file[unrecognizable_start:json['end']].export("temp.wav", format="wav")
else:
audio_file[json['start']:json['end']].export("temp.wav", format="wav")
temp_audio_file = sr.AudioFile('temp.wav')
with temp_audio_file as source:
audio = r.record(source)
try :
stt = r.recognize_google(audio_data = audio, language = "ko-KR")
# 통역 개시 지연시간
if num == 0:
silence = "(" + str(round(first_silence)) + "초).."
transcript_json.append({'start':0,'end':json['start'],'tag':'0000','result':silence})
first_silence_interval = first_silence
if unrecognizable_start != 0:
transcript_json.append({'start':unrecognizable_start,'end':json['end'],'tag':'1000','result':stt})
else:
transcript_json.append({'start':json['start'],'end':json['end'],'tag':'1000','result':stt})
unrecognizable_start = 0
num = num + 1
except:
if unrecognizable_start == 0:
unrecognizable_start = json['start']
statistics_filler_json.append({'어':filler_1, '음':filler_2, '그':filler_3})
statistics_silence_json.append({'통역개시지연시간':100 * first_silence_interval/audio_total_length, '침묵시간':100 * silence_interval/audio_total_length, '발화시간':100 * (audio_total_length - first_silence - silence_interval)/audio_total_length})
return transcript_json, statistics_filler_json, statistics_silence_json
드디어 통번역학과 스마트러닝을 위한 전사 API가 완성되었습니다! 다음과 같은 result가 포함된 전사 json파일과 통계 json파일을 구할 수 있습니다.


실제로 추임새 모델들을 사용해서 전사 알고리즘 API를 돌려보니 별도로 파라미터를 조정하지 않는 것이 더 높은 정확도를 보였습니다. 그래서 저희 팀은 기존 모델을 사용하기로 결정을 했습니다.
전사 결과입니다. 구글 STT와 비교해보면 그 차이점을 더 크게 알 수 있을 것입니다!
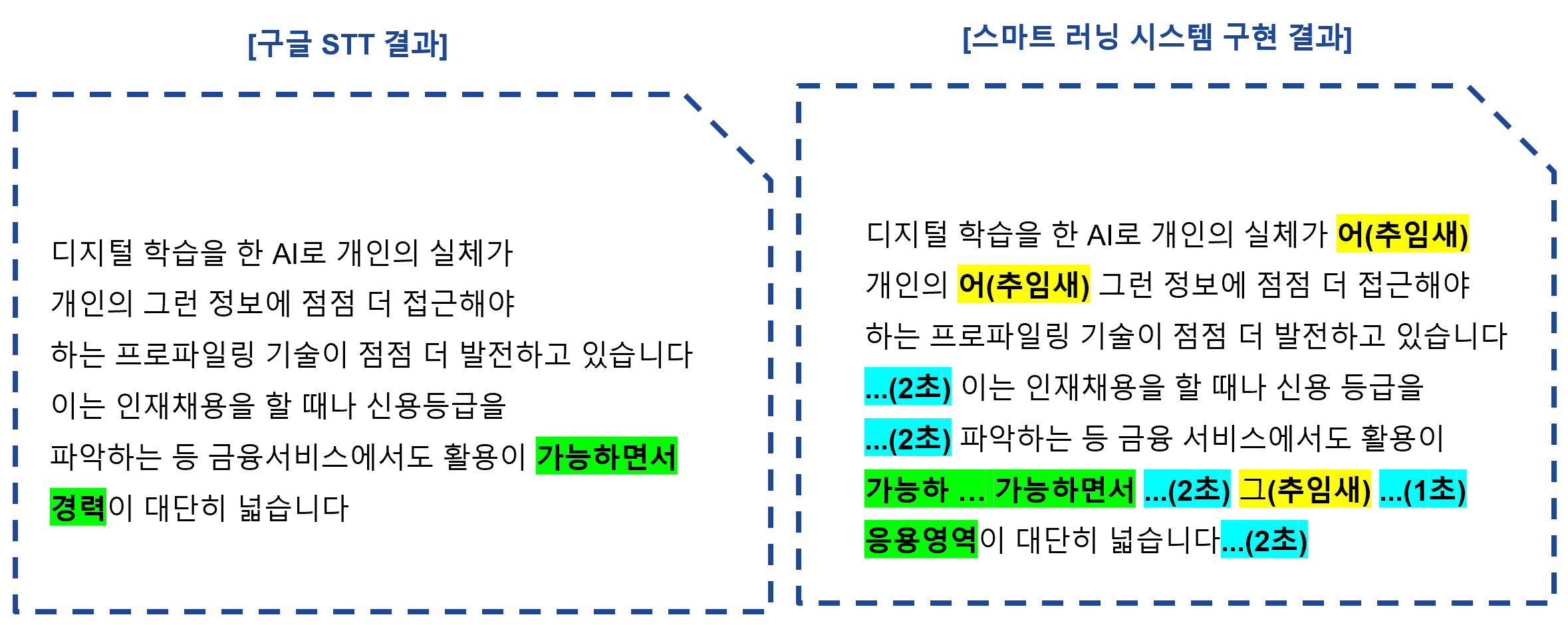
제가 맡은 부분을 간단히 설명하기 위해서 해당 블로그 글에는 생략된 코드들이 많습니다. 전체 코드는 저희 팀 깃허브에서 확인해주세요!
그로스3팀
그로스3팀 has 3 repositories available. Follow their code on GitHub.
github.com
감사합니다.
고유정
'졸업프로젝트' 카테고리의 다른 글
| 이화여대 통번역대학원 스마트러닝 시스템 (0) | 2020.11.14 |
|---|
